Going Indirect on UE3
The following is a simple algorithm that I used to change UE3’s renderer to use indirect rendering, and draw a large number of instanced meshes in a single batched draw. It requires DX11 feature set.
The key motivations were
- Support long draw distances and higher draw calls
- Reduce CPU time spent on rendering, which for the most part runs on a single thread
- Minimal artist intervention - it just works!
Overview
- At map build time, go through all the placed assets in the level and create an aggregate InstancedDrawBatch structure which contains instancing info and indirect args buffer (to be populated later). This is serialized out and saved with the level data.
- At map load time, load all the generated draw batches for the level.
- At runtime, launch a culling task per draw batch every frame. This performs frustum culling, occlusion culling (using HZB), projected bounds size culling, etc. The instance info for all instances that pass culling are copied over to another buffer which will be used during draw submission. The indirect args buffer is populated at the same time.
- Submit the indirect args buffer generated for each batch using
DrawIndexedInstancedIndirect()
Batch Resources
InstancedDrawBatch is an aggregate struct that holds all the information required to cull and render an instance group. The following is a concise and simplified C++ representation.
struct InstancedDrawBatch
{
FVertexBuffer vb; // Vertex buffer shared by all instances in batch
FIndexBuffer ib; // Index buffer shared by all instances in the batch
FIndexBuffer ib_pos; // Simplified IB with degenerate verts removed
FTypedBuffer vcolor; // Appended vert color data for every instance in the batch
FStructuredBuffer inst_buff; // Data unique to each instance - transforms, vcolor index, etc.
FStructuredBuffer inst_buff_draw;// Same as above but filled out after culling. *Not Serialized*
FConstantBuffer cbuffer; // Constant data for the batch
FMaterial mat; // Material used by each instance - uniform for entire batch
FLightingData light_info; // Atlassed lightmaps, shadowmaps, etc for the batch
FStructuredBuffer args_buff; // DrawIndirect args filled out after culling. *Not Serialized*
size_t num_instances; // Number of instances in the draw batch
};
The structured buffer for inst_buff has the following data. It contains data unique to each instance in the batch.
struct InstanceData
{
matrix3x3 local_to_world; // Local-to-world transform
vector4 lightmap_coord_scale_bias; // Lightmap atlas transform
vector4 wind_direction_and_speed; // Wind parameters. GPU-simulation. *Not Serialized*
float draw_distance; // For distance culling
unint32_t vert_color_index; // Index into InstanceColorBuffer
uint32_t vert_lighting_index; // Index into vertex lighting typed buffers
};
cbuffer holds data that is shared by all instances in the batch
struct ConstantData
{
vector3 bounds_origin;
float3 bounds_radius;
float3 bounds_extent;
size_t num_instances;
size_t num_verts_per_instance;
};
At render time, SV_InstanceID and SV_VertexID are used to retrieve the above information in a vertex shader. Since SV_InstanceID can only be input into the first active shader in the pipeline, it is passed as an attribute (without interpolation) to the pixel shader. That way the pixel shader can access the instancing data as well. See example below.
StructuredBuffer<InstanceData> PerInstanceData : register(t0);
Buffer<float4> BatchVertexColor : register(t1);
void vs_main(
...
uint instance_id : SV_InstanceID,
uint vertex_id : SV_VertexID,
out nointerpolation uint out_instance_id : InstanceID
out float4 pos : SV_Position,
)
{
// Retrieve instance transform from PerInstanceData structured buffer using SV_InstanceId
float3x3 inst_local_to_world = PerInstanceData[instance_id].local_to_world;
// Vertex color for all instances are appended end-to-end in a typed buffer.
// So, we need to perform an additional level of indirection when accessing it.
// First, get the offset of the vertex color data for this instance.
// Then use SV_Vertex id to access the color for that vert
uint vert_color_index = PerInstanceData[instance_id].vert_color_index;
uint offset_from_start = vert_color_index * num_verts_per_instance;
float4 vert_color = BatchVertexColor.Load(offset_from_start + vertex_id);
}
Culling
The culling phase rejects all the instances in a draw batch that fail visibility tests and generates the args buffer for the idirect draw call. This is run early in the frame, before any render passes. The previous frame’s z-buffer is used for occlusion culling.
The following is the skeleton structure for the culling shader
// Write buffers
RWStructuredBuffer<PerInstanceInfo> DrawInstanceBuffer : register(u0);
globallycoherent RWByteAddressBuffer DrawArgsDstBuffer : register(u1);
// Read buffers
StructuredBuffer<PerInstanceInfo> InstanceBuffer : register(t2);
[numthreads(64, 1, 1)]
void Main(uint3 DTid : SV_DispatchThreadID)
{
uint i = DTid.x;
// Intitialize num draw instances to 0
if (i == 0)
{
uint dummy;
DrawArgsDstBuffer.InterlockedExchange(4, 0, dummy);
}
// Sync
GroupMemoryBarrierWithGroupSync();
// Generate draw args and instance data
if (i < NumInstances)
{
// Expand bounding-box corner vertices into translated world space
float3 CornerVerts[8];
float3x4 LocalToWorld = GetLocalToWorld(i);
CornerVerts[0] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(-1.0f, -1.0f, -1.0f), 1.0f));
CornerVerts[1] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(-1.0f, -1.0f, 1.0f), 1.0f));
CornerVerts[2] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(-1.0f, 1.0f, -1.0f), 1.0f));
CornerVerts[3] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(-1.0f, 1.0f, 1.0f), 1.0f));
CornerVerts[4] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(1.0f, -1.0f, -1.0f), 1.0f));
CornerVerts[5] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(1.0f, -1.0f, 1.0f), 1.0f));
CornerVerts[6] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(1.0f, 1.0f, -1.0f), 1.0f));
CornerVerts[7] = mul(LocalToWorld, float4(BoundsOrigin + BoundsExtent * float3(1.0f, 1.0f, 1.0f), 1.0f));
// Compute new (scaled) radius
float3 WorldBoundsOrigin = 0.5f * (CornerVerts[0] + CornerVerts[7]);
float ScaledRadius = length(CornerVerts[7] - WorldBoundsOrigin);
// Distance cull
[branch]
if (DistanceCull(WorldBoundsOrigin, BoundsExtent, InstanceBuffer[i].MaxDrawDistance))
return;
// Frustum test
[branch]
if (FrustumCull(WorldBoundsOrigin, ScaledRadius))
return;
// Screen bounds
float MaxZ = 0.0;
float4 SBox;
bool bValidScreenBounds = GetScreenBounds(CornerVerts, MaxZ, SBox);
[branch]
if (bValidScreenBounds)
{
// Calculate projected area of the object bounds in screen space
float4 SBox_VP = SBox * ScreenSize.xyxy;
float ProjectedBoundsArea = (SBox_VP.z - SBox_VP.x) * (SBox_VP.w - SBox_VP.y);
// Projection area cull (catches primitives that weren't handled by distace cull)
[branch]
if (ProjectedBoundsArea < PIXEL_CULL_THRESHHOLD)
return;
// HZB occlusion test
[branch]
if (OcclusionCull(MaxZ, SBox))
return;
bEnableWorldPositionOffset = ProjectedBoundsArea > WORLD_POSITION_OFFSET_THRESHHOLD;
}
// Passed all culling tests, so append the instance data
uint writeIndex;
DrawArgsDstBuffer.InterlockedAdd(4, 1, writeIndex);
DrawInstanceBuffer[writeIndex] = InstanceBuffer[i];
// Wind Simulation
DrawInstanceBuffer[writeIndex].WindDirectionAndSpeed = SimulateWind(WorldBoundsOrigin.xyz);
}
}
The code below is used for frustum culling
bool FrustumCull(float3 WorldBoundsOrigin, float Radius)
{
for (uint i = 0; i < NumFrustumPlanes; ++i)
{
float PlaneDistance = dot(FrustumPlanes[i].xyz, WorldBoundsOrigin) - FrustumPlanes[i].w;
if (PlaneDistance > Radius)
{
return true;
}
}
return false;
}
The following snippet is used to get screen bounds, and perfrom HZB occlusion culling. The Z-Tests are reversed because we are using a reverse floating point depth buffer.
bool GetScreenBounds(float3 CornerVerts[8], out float MaxZ, out float4 SBox)
{
// Screen rect from bounds
float3 RectMin = float3(10000, 10000, 10000);
float3 RectMax = float3(-10000, -10000, -10000);
UNROLL for (int i = 0; i < 8; i++)
{
float4 PointClip = mul(ViewProjectionMatrix, float4(CornerVerts[i], 1.0));
/* Behind camera check. Bail out and trivially accept if any of the bounding box verts
are behind the camera as in that case you might end up with a projected area that is negative. This case usually happens when large meshes are viewed very close up, which would most likely pass culling anyway! */
[branch]
if (PointClip.w < 0)
return false;
float3 PointScreen = PointClip.xyz / PointClip.w;
RectMin = min(RectMin, PointScreen);
RectMax = max(RectMax, PointScreen);
}
MaxZ = RectMax.z;
SBox = saturate(float4(RectMin.xy, RectMax.xy) * float2(0.5, -0.5).xyxy + 0.5).xwzy;
return true;
}
bool OcclusionCull(float MaxZ, float4 SBox)
{
// Calculate HZB level.
float4 SBox_HZB = SBox * HZBSize.xyxy;
float2 Size = (SBox_HZB.zw - SBox_HZB.xy) * 0.5;
uint Level = ceil(log2(max(Size.x, Size.y)));
// If the projected bounds is greater than the lowest res HZB, trivially accept
if (Level >= NumHZBMips)
return false;
// Sample 4x4 from HiZ
float2 Scale = (SBox.zw - SBox.xy) / 3;
float2 Bias = SBox.xy;
float4 MinDepth = 1.f;
UNROLL for (int i = 0; i < 4; i++)
{
float4 Depth;
Depth.x = HZBTexture.SampleLevel(HZBSampler, float2(i, 0) * Scale + Bias, Level).r;
Depth.y = HZBTexture.SampleLevel(HZBSampler, float2(i, 1) * Scale + Bias, Level).r;
Depth.z = HZBTexture.SampleLevel(HZBSampler, float2(i, 2) * Scale + Bias, Level).r;
Depth.w = HZBTexture.SampleLevel(HZBSampler, float2(i, 3) * Scale + Bias, Level).r;
MinDepth = min(MinDepth, Depth);
}
MinDepth.x = min(min(MinDepth.x, MinDepth.y), min(MinDepth.z, MinDepth.w));
return MaxZ < MinDepth.x;
}
The following code shows a single pass of the HZB generation. Note that the HZB dimensions need to be a power of 2 for the downsampling to work correctly
// Reciprocal of the dimensions of the source and destination surfaces.
float2 RcpBufferDimSrc;
float2 RcpBufferDimDest;
static const float UVOffset = 0.25f;
[numthreads(WARP_SIZE, GROUP_SIZE, 1)]
void DownsampleCS(uint3 DispatchId : SV_DispatchThreadID)
{
uint2 ST = DispatchId.xy;
float2 Position = ST + 0.5;
float2 UV = Position * RcpBufferDimSrc;
float4 Depth;
Depth.x = DepthTexIn.SampleLevel(DepthTexInSampler, UV + float2(-UVOffset, -UVOffset) * RcpBufferDimDest, 0).r;
Depth.y = DepthTexIn.SampleLevel(DepthTexInSampler, UV + float2(UVOffset, -UVOffset) * RcpBufferDimDest, 0).r;
Depth.z = DepthTexIn.SampleLevel(DepthTexInSampler, UV + float2(-UVOffset, UVOffset) * RcpBufferDimDest, 0).r;
Depth.w = DepthTexIn.SampleLevel(DepthTexInSampler, UV + float2(UVOffset, UVOffset) * RcpBufferDimDest, 0).r;
float MinDepth = min(min(Depth.x, Depth.y), min(Depth.z, Depth.w));
DepthTexOut[DispatchId.xy] = MinDepth;
}
Rendering
Once the draw batches have been culled, they are submitted for rendering using DrawIndexedInstancedIndirect(). As is the case with indirect rendering, we have to submit draw calls for all the draw batches, even if all instances within it have been culled. Although the GPU cost for these “null” draws is fairly small, it is not neglibile. The CPU cost for these draws is the same as a any other draw call. As such, it is important to keep the number of draw batches low.
The solution I ended up using to mitigate this was to use a instance threshold for batching. Any asset that was re-used more than 32 times was considered for indirect rendering, all others fell back to using the old direct rendering codepath - essentially a hybrid solution.
The following shows some of the CPU perf gains achieved by going indirect.
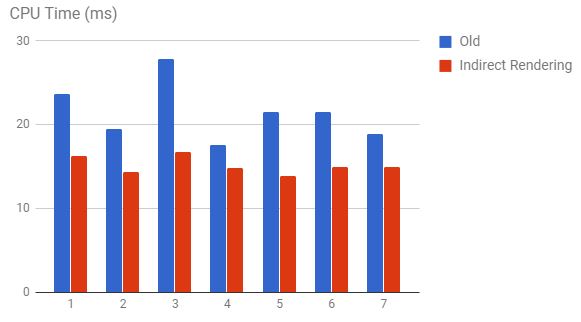
Caveats
Despitve the above performance gains, and the relative simplicity of the technique, here are a few things that don’t work so well.
- Unique Geometry - Since this technique groups instances by mesh and material for instancing, the mileage you get out of it is directly proportional to the number of instanced assets in view. It will not work well with scenes made up of a lot of unique assets.
- LODs - Although LODs can be supported by this technique by creating separate draw batches for each mesh LOD and culling them based on distance, doing so can double or triple the number of draw batches to be submitted each frame which increases the baseline cost. Our solution was to not use artist-authored LODs but instead, procedurally disable stuff in the culling pass based on distance such as vertex movement due to wind, etc. When doing that, it becomes important to do a depth prepass and force early Z to keep shading costs down in the base color/lighting pass.
Conclusion
Because draw submission and culling are offloaded to the GPU, the GPU has to be able to take on the additional work. The choice to not use LODs created extra GPU work as well. However, this was fine for our case because we were severely CPU limited by a single render thread, and the GPU utilization was poor as seen through GPUView. Going from a CPU-limited case to a GPU-limited one was a good trade-off for us, particularly because the CPU workload can be erratic - being GPU-bound offered more consistent and better framerates.
If the above constraints are acceptable, this can be a viable technique to using indirect rendering and instancing to optimize CPU time spent in rendering and push more detail. Thanks to @DrGr4f1x for his contribution on this, specially on the culling shaders.